Failed rows checks
Last modified on 10-Jul-24
Use a failed rows check to explicitly send samples of rows that failed a check to Soda Cloud.
You can also use a failed row check to configure Soda Library to execute a CTE or SQL query against your data, or to group failed check results by one or more categories.
checks for dim_customer:
# Failed rows defined using common table expression
- failed rows:
samples limit: 50
fail condition: total_children = '2' and number_cars_owned >= 3
checks for dim_customer:
# Failed rows defined using SQL query
- failed rows:
fail query: |
SELECT DISTINCT geography_key
FROM dim_customer as customer
✔️ Requires Soda Core Scientific (included in a Soda Agent)
✔️ Supported in Soda Core
✔️ Supported in Soda Library + Soda Cloud
✔️ Supported in Soda Cloud Agreements + Soda Agent
✔️ Available as a no-code check with a self-hosted Soda Agent connected to any
Soda-supported data source, except Spark, and Dask and Pandas
OR
with a Soda-hosted Agent connected to a BigQuery, Databricks SQL, MS SQL Server,
MySQL, PostgreSQL, Redshift, or Snowflake data source
Prerequisites
About failed row samples
Define failed rows checks
Optional check configurations
Set a sample limit
Disable failed rows sampling for specific columns
Configure in Soda Cloud
Configure in Soda Library
Disabling options and details
About failed rows sampling queries
Reroute failed rows samples
Configure a failed row sampler for programmatic scans
Go further
Prerequisites
- To use failed row checks to send failed rows samples to Soda Cloud, samples collection must not be disabled in Soda Cloud.
About failed row samples
When a scan results in a failed check, the CLI output displays information about the check that failed and why. To offer more insight into the data that failed a check, Soda Cloud displays failed rows in a check result’s history.
There are two ways you can configure a SodaCL check to send failed row samples to your Soda Cloud account:
- Implicitly: define a reference check, or use a duplicate_count or duplicate_percent metric, a missing metric, or a validity metric in your check. Checks that use these metrics automatically send 100 failed row samples to your Soda Cloud account.
- Explicitly: use failed rows checks to explicitly send failed rows to Soda Cloud. Read on!
Define failed rows checks
In the context of SodaCL check types, failed row checks are user-defined. This check is limited in its syntax variation, but you can customize your expression or query as much as you like.
The example below uses common table expression (CTE) to define the fail condition that any rows in the dim_customer dataset must meet in order to qualify as failed rows, during a scan, get sent to Soda Cloud.
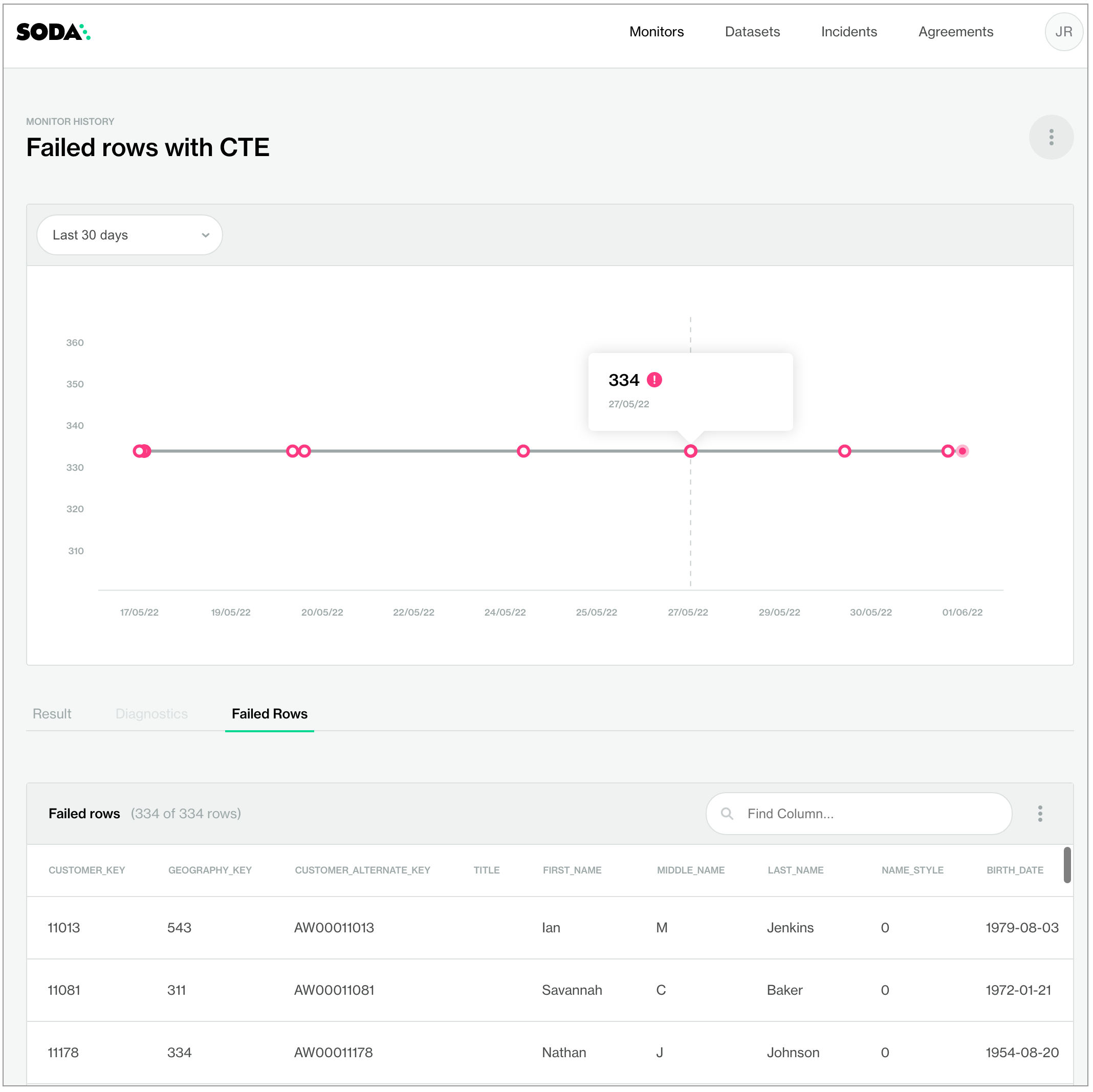
In this rather silly example, Soda sends any rows which contain the value 2 in the total_children column and which contain a value greater than or equal to 3 in the number_cars_owned column to Soda Cloud as failed row samples. The check also uses the name configuration key to customize a name for the check so that it displays in a more readable form in Soda Cloud; see image below.
checks for dim_customer:
- failed rows:
name: Failed rows with CTE
fail condition: total_children = '2' and number_cars_owned >= 3
# OR
- failed rows:
name: Failed rows with CTE
fail condition: |
total_children = '2' and number_cars_owned >= 3
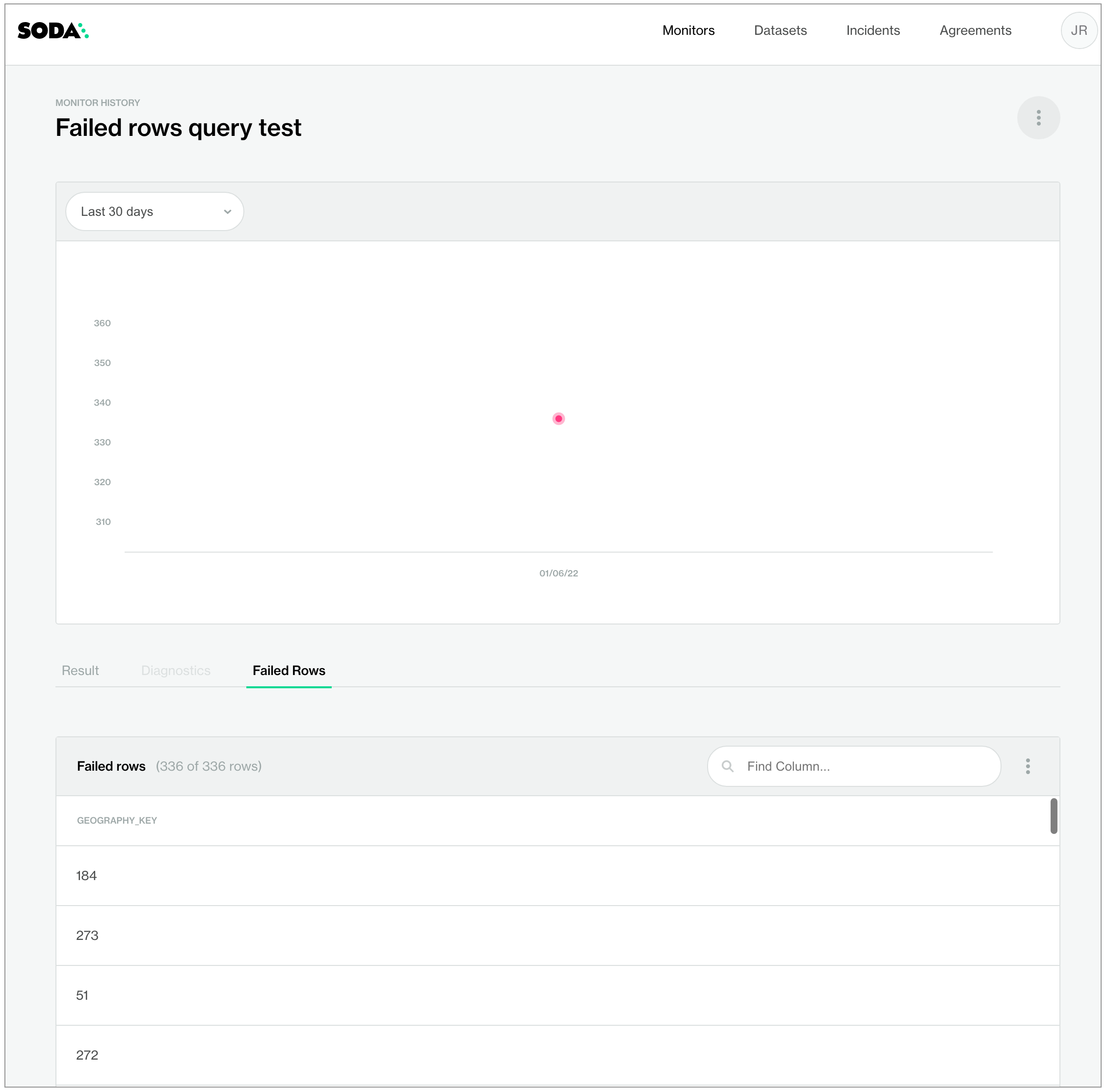
If you prefer, you can use a SQL query to define what qualifies as a failed row for Soda to send to Soda Cloud, as in the following simple example. Use this cofiguration to include complete SQL queries in the Soda scan of your data.
checks for dim_customer:
- failed rows:
fail query: |
SELECT DISTINCT geography_key
FROM dim_customer as customer
Optional check configurations
| Supported | Configuration | Documentation |
|---|---|---|
| ✓ | Define a name for a failed rows check; see example. | Customize check names |
| ✓ | Add an identity to a check. | Add a check identity |
| ✓ | Define alert configurations to specify warn and fail alert conditions; see example. | Add alert configurations |
| Apply an in-check filter to return results for a specific portion of the data in your dataset. | - | |
| ✓ | Use quotes when identifying dataset or column names; see example. Note that the type of quotes you use must match that which your data source uses. For example, BigQuery uses a backtick (`) as a quotation mark. | Use quotes in a check |
| ✓ | Use wildcard characters in the value in the check. | Use wildcard values as you would with CTE or SQL. |
| Use for each to apply failed rows checks to multiple datasets in one scan. | - | |
| ✓ | Apply a dataset filter to partition data during a scan; see example. Known issue: Dataset filters are not compatible with failed rows checks which use a SQL query. With such a check, Soda does not apply the dataset filter at scan time. | Scan a portion of your dataset |
Example with check name
checks for dim_customer:
- failed rows:
name: Failed rows query test
fail query: |
SELECT DISTINCT geography_key
FROM dim_customer as customer
Example with alert
checks for dim_customer:
- failed rows:
samples limit: 50
fail condition: total_children = '2' and number_cars_owned >= 3
warn: when between 1 and 10
fail: when > 10
Example with quotes
checks for dim_customer:
- failed rows:
name: Failed rows query test
fail query: |
SELECT DISTINCT "geography_key"
FROM dim_customer as customer
Example with dataset filter
Known issue: Dataset filters are not compatible with failed rows checks which use a SQL query. With such a check, Soda does not apply the dataset filter at scan time.
filter dim_product [new]:
where: start_date < TIMESTAMP '2015-01-01'
checks for dim_product [new]:
- failed rows:
name: Failed CTE with filter
fail condition: weight < '200' and reorder_point >= 3
Set a sample limit
By default, Soda sends 100 failed row samples to Soda Cloud. You can limit the number of sample rows that Soda sends using the samples limit configuration key:value pair, as in the following example.
checks for dim_customer:
- failed rows:
samples limit: 50
fail condition: total_children = '2' and number_cars_owned >= 3
If you wish to prevent Soda from collecting and sending failed row samples to Soda Cloud for an individual check, you can set the samples limit to 0. Alternatively, you can disable all samples for all your data; see Disable samples in Soda Cloud.
checks for dim_customer:
- failed rows:
samples limit: 0
fail condition: total_children = '2' and number_cars_owned >= 3
If you wish to set a limit on the samples that Soda collects for an entire data source, you can do so by adjusting the configuration YAML file, or editing the Data Source connection details in Soda Cloud, as per the following syntax.
data_source soda_test:
type: postgres
host: xyz.xya.com
...
sampler:
samples_limit: 99
Additionally, you can Disable failed rows sampling for specific columns.
Disable failed rows sampling for specific columns
For checks which implicitly or explicitly collect failed rows samples, you can add a configuration to prevent Soda from collecting failed rows samples from specific columns that contain sensitive data.
See also:
- Set a sample limit to
0on an individual check to avoid collecting or sending failed row samples. - Set a sample limit for an entire data source.
For example, you may wish to exclude a column that contains personal identifiable information (PII) such as credit card numbers from the Soda query that collects samples.
To do so, add the sampler configuration to your data source connection configuration to specify the columns you wish to exclude, as per the following examples.
data_source my_datasource_name:
type: postgres
host: localhost
port: '5432'
username: ***
password: ***
database: postgres
schema: public
sampler:
exclude_columns:
dataset_name:
- column_name1
- column_name2
dataset_name_other:
- column_nameA
- column_nameB
OR
data_source my_datasource_name:
type: postgres
...
sampler:
exclude_columns:
dataset_name: [column_name1, column_name2]
dataset_name_other: [column_nameA, column_nameB]
Configure in Soda Cloud
- As an Admin user, log in to Soda Cloud, then navigate to an existing data source: your avatar > Data Sources.
- In the Data Sources tab, click to open the data source that contains the columns in the dataset that you wish to exclude from failed rows sampling, then navigate to the Connect the Data Source tab.
- To the connection configuration, add the
samplerconfiguration as outlined above. - Save the changes.
Alternatively, you can disable the failed row samples feature entirely in Soda Cloud; see Disable failed row samples for details.
Configure in Soda Library
- Open the configuration YAML file that contains the data source connection configuration for the data source that contains the dataset that contains the columns that you wish to exclude from failed rows sampling.
- To the connection configuration, add the
samplerconfiguration above to specify the columns you wish to exclude, as outlined above. - Save the changes to the file.
Disabling options and details
Optionally, you can use wildcard characters * in the sampler configuration, as in the following examples.
# disable all failed rows samples on all datasets
sampler:
exclude_columns:
'*': ['*']
# disable failed rows samples on all columns named "password" in all datasets
sampler:
exclude_columns:
'*': [password]
# disable failed rows samples on the "last_name" column and all columns that begin with "pii_" from all datasets that begin with "soda_"
sampler:
exclude_columns:
soda_*: [last_name, pii_*]
- Soda executes the
exclude_columnsvalues cumulatively. For example, for the following configuration, Soda excludes the columnspassword,last_nameand any columns that begin withpii_from theretail_customersdataset.
sampler:
exclude_columns:
retail_*: [password]
retail_customers: [last_name, pii_*]
-
The
exclude_columnsconfiguration also applies to any custom, user-defined failed rows sampler. -
The
exclude_columnsconfiguration does not apply to sample data collection. -
Checks in which you provide a complete SQL query, such as failed rows checks that use a
fail query, do not honor theexclude_columnconfiguration. Instead, a gatekeeper component parses all queries that Soda runs to collect samples and ensures that none of columns listed in anexclude_columnconfiguration slip through when generating the sample queries. In such a case, the Soda Library CLI provides a message to indicate the gatekeeper’s behavior:Skipping samples from query 'retail_orders.last_name.failed_rows[missing_count]'. Excluded column(s) present: ['*'].
About failed rows sampling queries
For the most part, when you exclude a column from failed rows sampling, Soda does not include the column in its query to collect samples. In other words, it does not collect the samples then prevent them from sending to Soda Cloud, Soda does not query the column for samples, period. (There are some edge cases in which this is not the case and for those instances, a gatekeeper component ensures that no excluded columns are included in failed rows samples.)
As an example, imagine a check that looks for NULL values in a column that you included in your exclude_columns configuration. (A missing metric in a check implicitly collects failed rows samples.)
checks for retail_orders:
- missing_count(cat) = 0
If the cat column were not an excluded column, Soda would generate two queries:
- a query that executes the check
- another query to collect failed rows samples for checks that failed
SELECT * FROM dev_m1n0.sodatest_customers_6c2f3574
WHERE cat IS NULL
Query soda_test.cat.failed_rows[missing_count]:
SELECT * FROM dev_m1n0.sodatest_customers_6c2f3574
WHERE cat IS NULL
But because the cat column is excluded, Soda must generate three queries:
- a query that executes the check
- a query to gather the schema of the dataset to identify all columns
- another query to collect failed rows samples for checks that failed, only on columns identified on the list returned by the preceding query
SELECT
COUNT(CASE WHEN cat IS NULL THEN 1 END)
FROM sodatest_customers
Query soda_test.get_table_columns_sodatest_customers:
SELECT column_name, data_type, is_nullable
FROM information_schema.columns
WHERE lower(table_name) = 'sodatest_customers'
AND lower(table_catalog) = 'soda'
AND lower(table_schema) = 'dev_1'
ORDER BY ORDINAL_POSITION
Skipping columns ['cat'] from table 'sodatest_customers' when selecting all columns data.
Query soda_test.cat.failed_rows[missing_count]:
SELECT id, cst_size, cst_size_txt, distance, pct, country, zip, email, date_updated, ts, ts_with_tz FROM sodatest_customers
WHERE cat IS NULL
Reroute failed rows samples
If the data you are checking contains sensitive information, you may wish to send any failed rows samples that Soda collects to a secure, internal location rather than Soda Cloud.
To do so, configure a custom failed row sampler to receive the failed rows into a JSON and then convert them into the format you need. Then, add the storage configuration to your sampler configuration in your data source connection configuration.
Soda sends the failed rows samples as a JSON event payload and includes the following, as in the example below.
- data source name
- dataset name
- scan definition name
- check name
{
"check_name": "String",
"count": "Integer",
"dataset": "String",
"datasource": "String",
"rows": [
{
"column1": "String|Number|Boolean",
"column2": "String|Number|Boolean"
...
}
],
"schema": [
{
"name": "String",
"type": "String"
}
]
}
- Configure a custom failed row sampler; see example.
- As an Admin user, log in to Soda Cloud, then navigate to an existing data source: your avatar > Data Sources.
- In the Data Sources tab, click to open the data source for which you wish to reroute failed rows samples, then navigate to the Connect the Data Source tab.
- To the connection configuration, add the
storageconfiguration as outlined below, then save.data_source my_datasource_name: type: postgres host: localhost port: '5432' username: *** password: *** database: postgres schema: public sampler: storage: type: http url: http://failedrows.example.com message: Failed rows have been sent to link: https://www.example.url link_text: S3
| Parameter | Value | Description |
|---|---|---|
type | http | Provide an HTTP endpoint such as a Lambda function, or a custom Python HTTP service. |
url | any URL | Provide a valid URL that accepts JSON payloads. |
message | any string | (Optional) Provide a customized message that Soda Cloud displays in the failed rows tab, prepended to the sampler response, to instruct your fellow Soda Cloud users how to find where the failed rows samples are stored in your environment. For example, if you wish the complete message to read: “Failed rows have been sent to dir/file.json”, configure the syntax as in the example above and return the file location path in the sampler’s response. |
link | any URL | (Optional) Provide a link to a web application through which users can access the stored sample. |
link_text | any string | (Optional) Provide text for the link button. For example, “View Failed Samples”. |
- Configure a custom failed row sampler; see example.
- Open the configuration YAML file that contains the data source connection configuration for the data source for which you wish to reroute failed rows samples.
- To the connection configuration, add the
storageconfiguration to specify the columns you wish to exclude, as outlined below, then save the changes to the file.data_source my_datasource_name: type: postgres host: localhost port: '5432' username: *** password: *** database: postgres schema: public sampler: storage: type: http url: http://failedrows.example.com message: Failed rows have been sent to link: https://www.example.url link_text: S3
| Parameter | Value | Description |
|---|---|---|
type | http | Provide an HTTP endpoint such as a Lambda function, or a custom Python HTTP service. |
url | any URL | Provide a valid URL that accepts JSON payloads. |
message | any string | (Optional) Provide a customized message that Soda Cloud displays in the failed rows tab, prepended to the sampler response, to instruct your fellow Soda Cloud users how to find where the failed rows samples are stored in your environment. For example, if you wish the complete message to read: “Failed rows have been sent to dir/file.json”, configure the syntax as in the example above and return the file location path in the sampler’s response. |
link | any URL | (Optional) Provide a link to a web application through which users can access the stored sample. |
link_text | any string | (Optional) Provide text for the link button. For example, “View Failed Samples”. |
Example: Custom failed row sampler
The following is an example of a custom failed row sampler that gets the failed rows from the Soda event object (JSON payload, see example below) and prints the failed rows in CSV format.
Borrow from this example to create your own custom sampler that you can use to reroute failed row samples.
import csv
import io
# Function to put failed row samples in a AWS Lambda / Azure function / Google Cloud function
def lambda_handler(event):
check_name = event['check_name']
count = event['count']
dataset = event['dataset']
datasource = event['datasource']
rows = event['rows']
schema = event['schema']
csv_buffer = io.StringIO()
# Write data to CSV buffer
csv_writer = csv.writer(csv_buffer)
# Write row header
header_row = [column['name'] for column in schema]
csv_writer.writerow(header_row)
# Write each row of data
for row in rows:
csv_writer.writerow(row)
# Move to the beginning of the buffer
csv_buffer.seek(0)
# Read the content of the buffer
csv_content = csv_buffer.getvalue()
# Print the content
print(csv_content)
Example CSV output:
column_1_name,column_2_name
row_1_column_1_value,row_1_column_2_value
row_2_column_1_value,row_2_column_2_value
Configure a failed row sampler for programmatic scans
If you are running Soda scans programmatically, you can add a custom sampler to collect samples of rows with a fail check result. Refer to the following example that prints the failed row samples in the CLI.
💡 Copy+paste and run an example script locally to print failed row samples in the CLI scan output.
from soda.scan import Scan
from soda.sampler.sampler import Sampler
from soda.sampler.sample_context import SampleContext
# Create a custom sampler by extending the Sampler class
class CustomSampler(Sampler):
def store_sample(self, sample_context: SampleContext):
# Retrieve the rows from the sample for a check.
rows = sample_context.sample.get_rows()
# Check SampleContext for more details that you can extract.
# This example simply prints the failed row samples.
print(sample_context.query)
print(sample_context.sample.get_schema())
print(rows)
if __name__ == '__main__':
# Create Scan object.
s = Scan()
# Configure an instance of custom sampler.
s.sampler = CustomSampler()
s.set_scan_definition_name("test_scan")
s.set_data_source_name("aa_vk")
s.add_configuration_yaml_str(f"""
data_source test:
type: postgres
schema: public
host: localhost
port: 5433
username: postgres
password: secret
database: postgres
""")
s.add_sodacl_yaml_str(f"""
checks for dim_account:
- invalid_percent(account_type) = 0:
valid format: email
""")
s.execute()
print(s.get_logs_text())
Save failed row samples to alternate desination
If you prefer to send the output of the failed row sampler to a destination other than Soda Cloud, you can do so by customizing the sampler as above, then using the Python API to save the rows to a JSON file. Refer to Python docs for Reading and writing files for details.
Go further
- Learn more about SodaCL metrics and checks in general.
- Borrow user-defined check syntax to define a resuable check template.
- Use a schema check to discover missing or forbidden columns in a dataset.
- Need help? Join the Soda community on Slack.
- Reference tips and best practices for SodaCL.
Was this documentation helpful?
What could we do to improve this page?
- Suggest a docs change in GitHub.
- Share feedback in the Soda community on Slack.
Documentation always applies to the latest version of Soda products
Last modified on 10-Jul-24