Sample data with Soda
Last modified on 08-Aug-24
When you add or edit a data source in Soda Cloud, use the sample datasets configuration to send 100 sample rows to Soda Cloud. Examine the sample rows to gain insight into the type of checks you can prepare to test for data quality.
sample datasets:
datasets:
- dim_customer
- include prod%
- exclude test%
✖️ Requires Soda Core Scientific (included in a Soda Agent)
✖️ Supported in Soda Core
✔️ Supported in Soda Library + Soda Cloud
✔️ Supported in Soda Cloud Agreements + Soda Agent
Sample datasets
Add quotes to all datasets
Inclusion and exclusion rules
Disable samples in Soda Cloud
Specify columns for failed row sampling
Go further
Sample datasets
Sample datasets captures sample rows from datasets you identify. You add sample datasets configurations as part of the guided workflow to create a new data source or edit an existing one. Navigate to your avatar > Data Sources > New Data Source, or select an existing data source, to begin. You can add this configuration to one of two places:
- to either step 3. Discover Datasets
OR - or step 4. Profile Datasets
The example configuration below uses a wildcard character (%) to specify that Soda Library sends sample rows to Soda Cloud for all datasets with names that begin with customer, and not to send samples for any dataset with a name that begins with test.
sample datasets:
datasets:
- include customer%
- exclude test%
You can also specify individual datasets to include or exclude, as in the following example.
sample datasets:
datasets:
- include retail_orders
Scan results in Soda Cloud
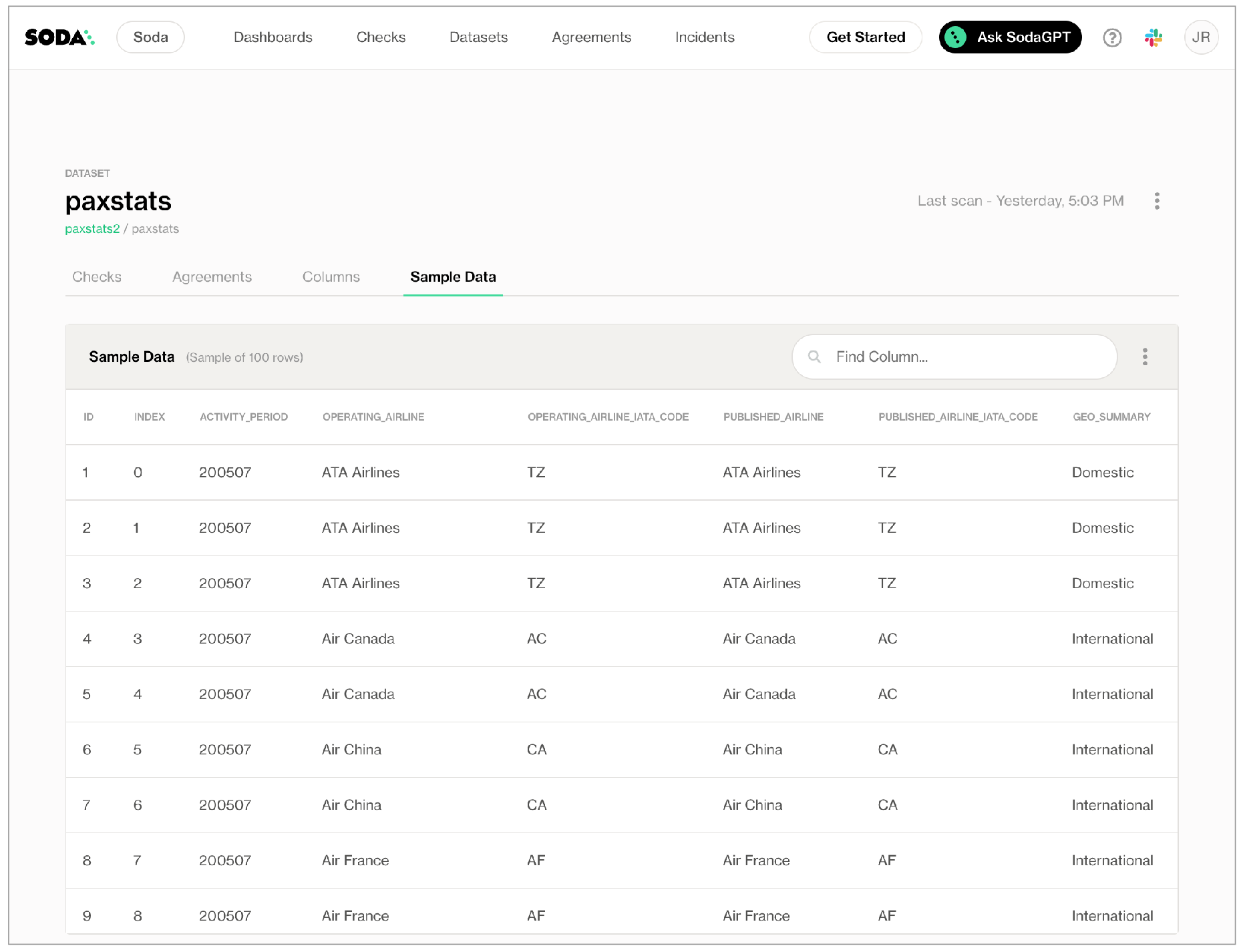
- To review the sample rows in Soda Cloud, first run a scan of your data source so that Soda can gather and send samples to Soda Cloud.
- In Soda Cloud, navigate to the Datasets dashboard, then click a dataset name to open the dataset’s info page.
- Access the Sample Data tab to review the sample rows.
Add quotes to all datasets
If your dataset names include white spaces or use special characters, you must wrap those dataset names in quotes whenever you identify them to Soda, such as in a checks YAML file.
To add those necessary quotes to dataset names that Soda acts upon automatically – discovering, profiling, or sampling datasets, or creating automated monitoring checks – you can add a quote_tables configuration to your data source, as in the following example.
data_source soda_demo:
type: sqlserver
host: localhost
username: ${SQL_USERNAME}
password: ${SQL_PASSWORD}
quote_tables: true
Inclusion and exclusion rules
- If you configure
sample datasetsto include specific datasets, Soda implicitly excludes all other datasets from sampling. - If you combine an include config and an exclude config and a dataset fits both patterns, Soda excludes the dataset from sampling.
Disable samples in Soda Cloud
Where your datasets contain sensitive or private information, you may not want to send samples from your data source to Soda Cloud. In such a circumstance, you can disable the feature completely in Soda Cloud.
To prevent Soda Cloud from receiving any sample data or failed row samples for any datasets in any data sources to which you have connected your Soda Cloud account, proceed as follows:
- As an Admin, log in to your Soda Cloud account and navigate to your avatar > Organization Settings.
- In the Organization tab, check the box to “Disable collecting samples and failed rows for metrics in Soda Cloud”, then Save.
Alternatively, if you use Soda Library, you can adjust the configuration in your configuration.yml to disable all samples, as in the following example.
data_source my_datasource:
type: postgres
...
sampler:
disable_samples: True
Note that you cannot use an exclude_columns configuration to disable sample row collections from specific columns in a dataset. That configuration applies only to disabling failed rows sampling.
Specify columns for failed row sampling
Migrate to Soda Library in minutes to start using this feature for free with a 45-day trial.
Beyond collecting samples of data from datasets, you can also use a samples columns configuration to an individual check to specify the columns for which Soda must implicitly collect failed row sample values. Soda only collects the check’s failed row samples for the columns you specify in the list, as in the duplicate_count example below.
Soda implicitly collects failed row samples for the following checks:
- reference check
- checks that use a missing metric
- checks that use a validity metric
- checks that use a duplicate_count or duplicate_percent metric
Note that the comma-separated list of samples columns does not support wildcard characters (%).
checks for dim_customer:
- duplicate_count(email_address) < 50:
samples columns: [last_name, first_name]
See also: About failed row samples
Go further
- Need help? Join the Soda community on Slack.
- Reference tips and best practices for SodaCL.
- Use a freshness check to gauge how recently your data was captured.
- Use reference checks to compare the values of one column to another.
Was this documentation helpful?
What could we do to improve this page?
- Suggest a docs change in GitHub.
- Share feedback in the Soda community on Slack.
Documentation always applies to the latest version of Soda products
Last modified on 08-Aug-24