Profile data with Soda
Last modified on 17-Jul-24
When you add or edit a data source in Soda Cloud, use the discover datasets and/or profile columns configurations to automatically profile data in your data source.
- Examine the profile information to gain insight into the type of SodaCL checks you can prepare to test for data quality.
- Use profiled data to create no-code data quality checks.
 Activate an anomaly dashboard to automatically gain observability insight into data quality.
Activate an anomaly dashboard to automatically gain observability insight into data quality.
discover datasets:
datasets:
- prod% # all datasets starting with prod
- include prod% # same as above
- exclude dev% # exclude all datasets starting with dev
profile columns:
columns:
- datasetA.columnA # columnA of datasetA
- datasetA.% # all columns of datasetA
- dataset%.columnA # columnA of all datasets starting with dataset
- dataset%.% # all columns of datasets starting with dataset
- "%.%" # all datasets and all columns
- include datasetA.% # same as datasetA.%
- exclude datasetA.prod% # exclude all columns starting with prod in datasetA
- exclude dimgeography.% # exclude all columns of dimgeography dataset
✔️ Requires Soda Core Scientific (included in a Soda Agent)
✖️ Supported in Soda Core
✔️ Supported in Soda Library + Soda Cloud
✔️ Supported in Soda Cloud + self-hosted Soda Agent connected to any
Soda-supported data source, except Spark, and Dask and Pandas
✔️ Supported in Soda Cloud + Soda-hosted Agent connected to a BigQuery, Databricks SQL,
MS SQL Server, MySQL, PostgreSQL, Redshift, or Snowflake data source
Add dataset discovery
Add column profiling
Add quotes to all datasets
Compute consumption and cost considerations
Inclusion and exclusion rules
Limitations and known issues
Go further
Add dataset discovery
Dataset discovery captures basic information about each dataset, including a dataset’s schema and the data type of each column. You add dataset discovery as part of the guided workflow to create a new data source. Navigate to your avatar > Data Sources > New Data Source to begin.
In step 3 of the guided workflow, you have the option of listing the datasets you wish to profile. Dataset discovery can be resource-heavy, so carefully consider the datasets about which you truly need profile information. Refer to Compute consumption and cost considerations for more detail.
SodaCL supports SQL wildcard characters such as %, *, or _. Refer to your data source’s documentation to determine which SQL wildcard characters it supports and how to escape the characters, such as with a backslash \, if your dataset or column names use characters that SQL would consider wildcards.
The example configuration below uses a wildcard character (%) to specify that, during a scan, Soda Library discovers all the datasets the data source contains except those with names that begin with test.
discover datasets:
datasets:
- include %
- exclude test%
The example configuration below uses a wildcard character (_). During a scan, Soda discovers all the datasets that start with customer and any single character after that, such as customer1, customer2, customer3. However, in the example below, Soda does not include dataset names that are exactly eight characters or are more than nine characters, as with customer or customermain.
discover datasets:
datasets:
- include customer_
The example configuration below uses both an escaped wildcard character (\_) and wildcard character(*). During a scan, Soda discovers all the datasets that start with north_ and any single or multiple character after that. For example, it includes north_star, north_end, north_pole. Note that your data source may not support backslashes to escape a character, so you may need to use a different escape character.
discover datasets:
datasets:
- include north\_*
You can also specify individual datasets to include or exclude, as in the following example.
discover datasets:
datasets:
- include retailorders
Disable dataset discovery
If your data source is very large, you may wish to disable dataset discovery completely. To do so, you can use the following configuration.
discover datasets:
datasets:
- exclude %
Access dataset profile information
After you have added the data source in Soda Cloud and the first scan to profile your data is complete, you can review the discovered datasets in Soda Cloud.
Navigate to the Datasets dashboard, then click a dataset name to open the dataset’s info page. Access the Columns tab to review the datasets that Soda Library discovered, including the type of data each column contains.
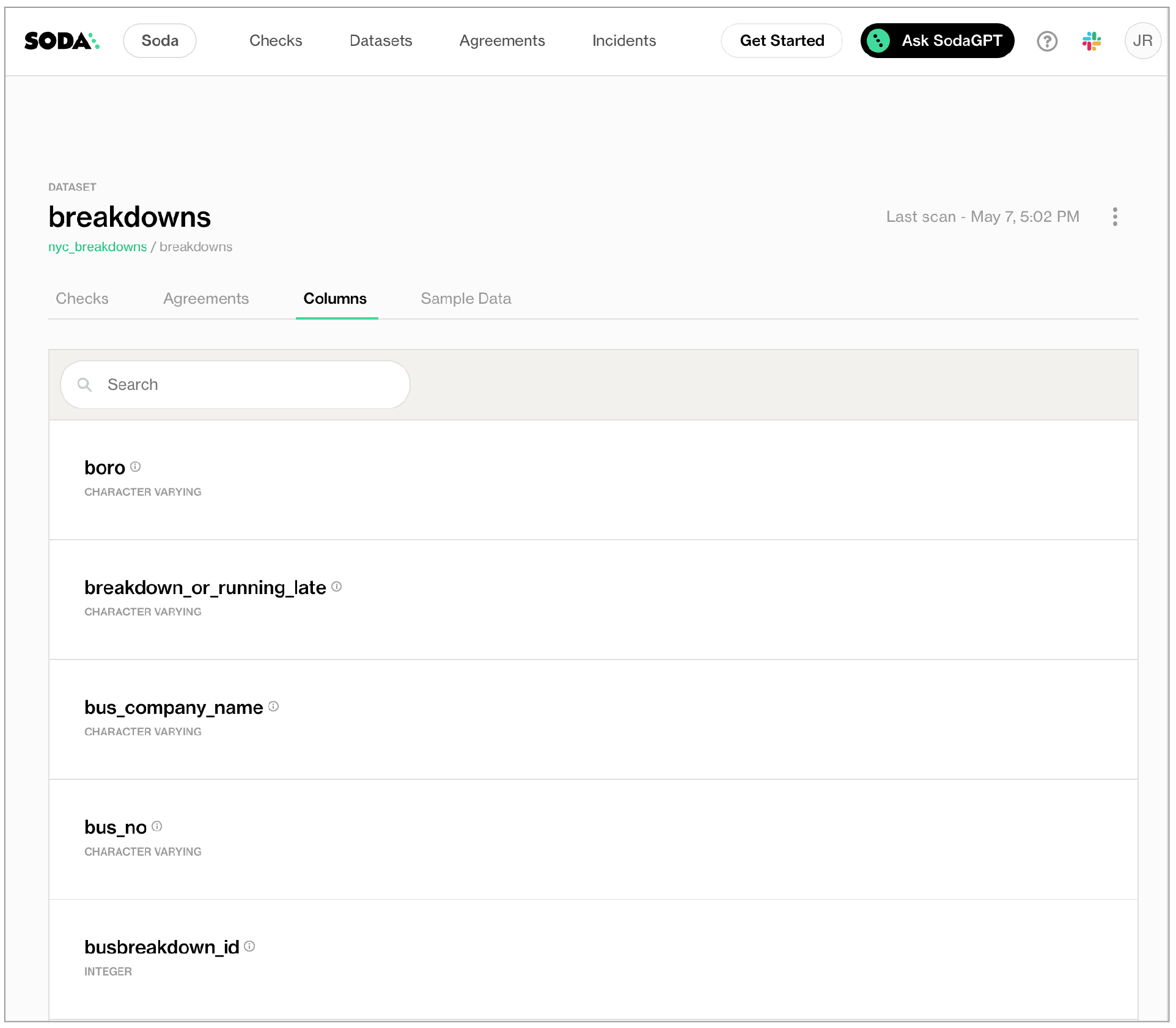
Add column profiling
Column profile information includes details such as the calculated mean value of data in a column, the maximum and minimum values in a column, and the number of rows with missing data.
Depending on your deployment model, or flavor, of Soda, profiling a dataset produces one or two tabs’ worth of data in a Dataset page in Soda Cloud.
| Flavor of Soda | Includes Column tab output | Includes Anomalies tab output |
|---|---|---|
| Self-operated |  | |
| Soda-hosted agent | | |
| Self-hosted agent | | |
| Programmatic | |
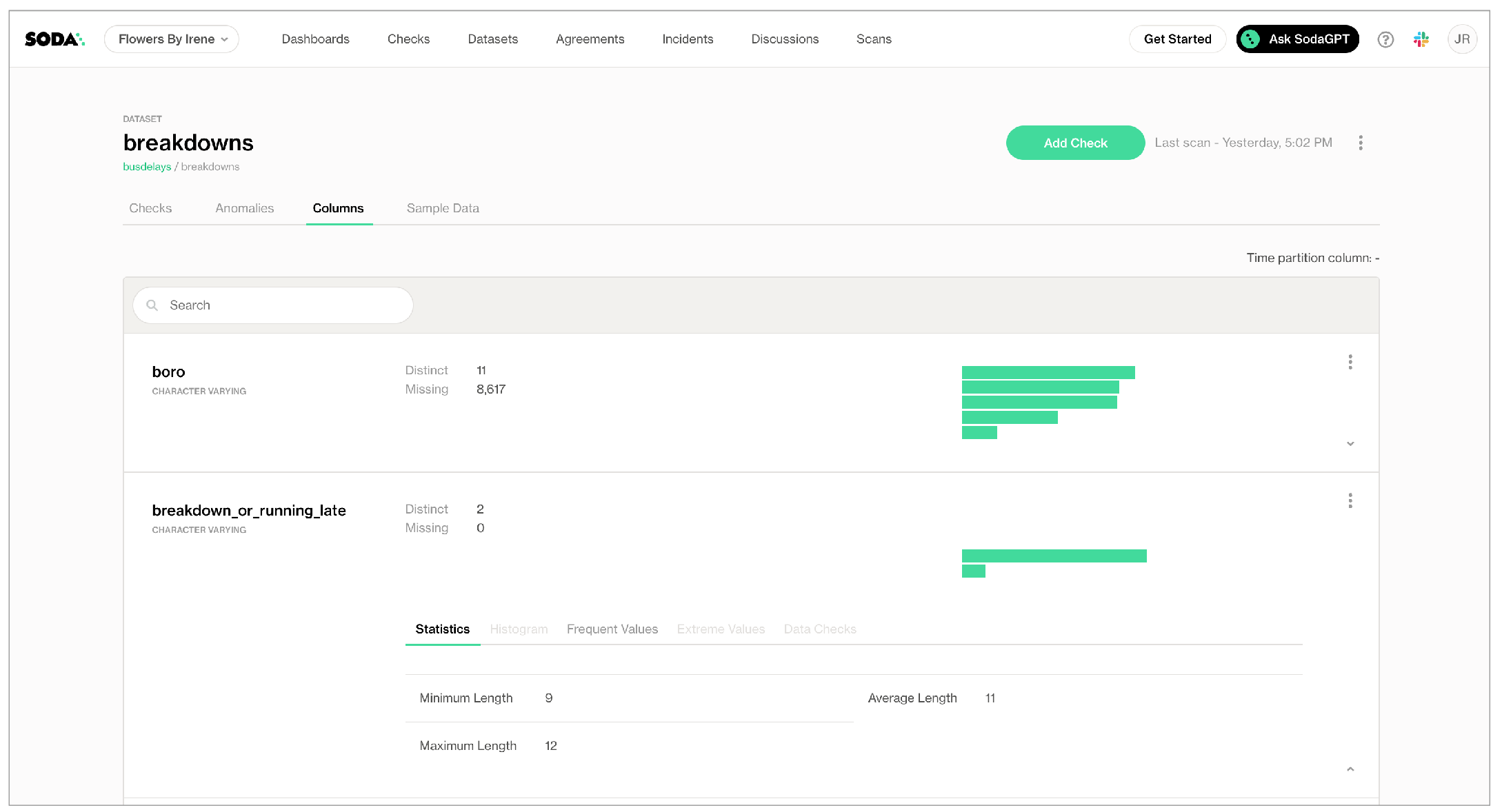
In the Columns tab, you can see column profile information including details such as the calculated mean value of data in a column, the maximum and minimum values in a column, and the number of rows with missing data.
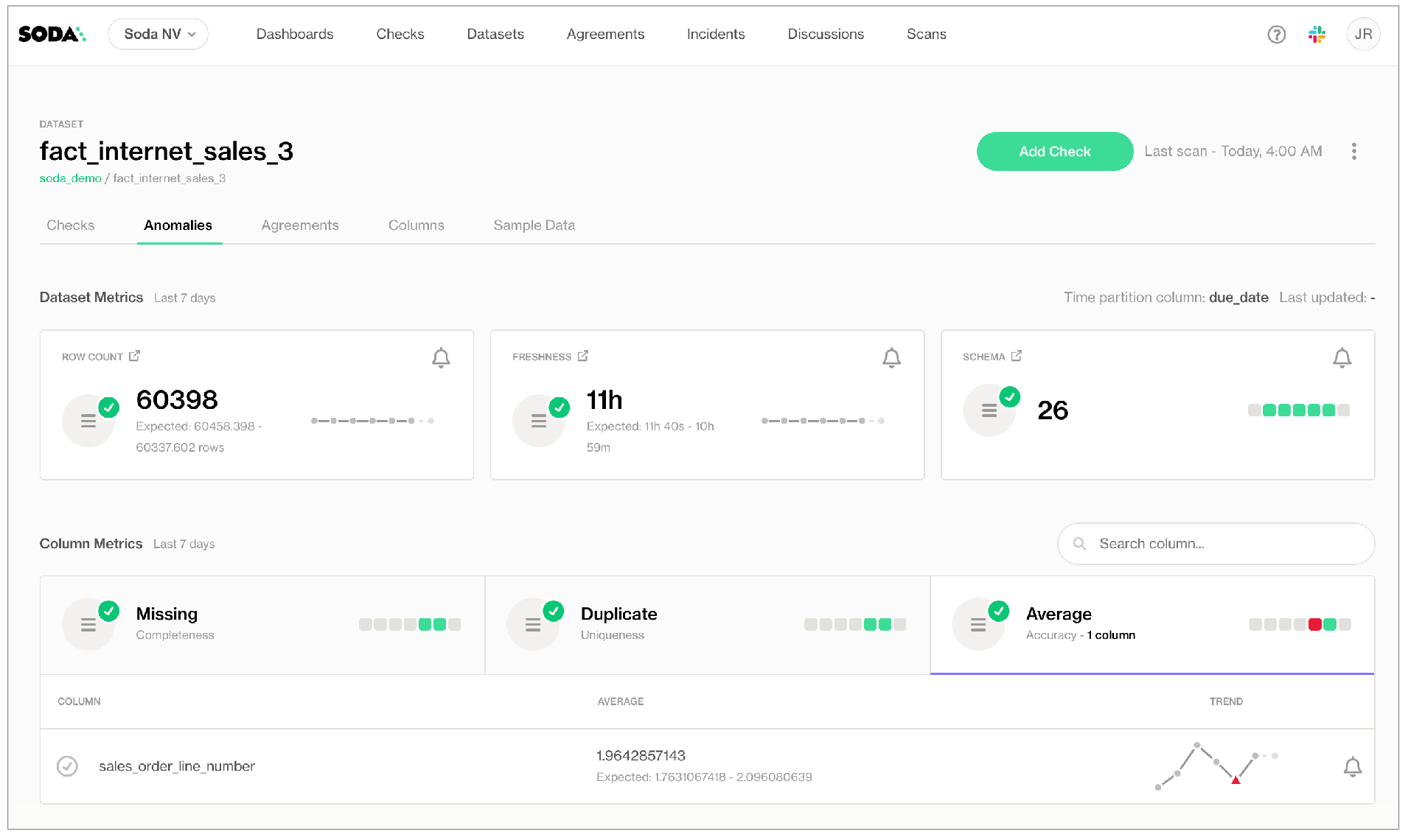
In the Anomalies tab, you can access an out-of-the-box anomaly dashboard that uses the column profile information to automatically begin detecting anomalies in your data relative to the patterns the machine learning algorithm learns over the course of approximately five days. Learn more
Add column profiling configuration
In Soda Cloud, you add column profiling as part of the guided workflow to create a new data source. Navigate to your avatar > Data Sources > New Data Source to begin.
For preview participants, only
If you have already added a data source to your Soda Cloud account via a self-hosted or Soda-hosted agent and wish to activate an anomaly dashboard for one or more datasets, refer to the activation instructions.
If you are using a self-operated deployment model that leverages Soda Library, add the column profiling configuration outlined below to your checks YAML file.
In step 4 of the guided workflow, or in your checks YAML file, add configuration to list the columns of datasets you wish to profile.
- Be aware that Soda can only profile columns that contain NUMBERS or TEXT type data; it cannot profile columns that contain TIME or DATE data except to create a freshness check for the anomaly dashboard.
- Soda performs the Discover datasets and Profile datasets actions independently, relative to each other. If you define exclude or include rules in the Discover tab, the Profile configuration does not inherit the Discover rules. For example, if, for Discover, you exclude all datasets that begin with
staging_, then configure Profile to include all datasets, Soda discovers and profiles all datasets. - Column profiling can be resource-heavy, so carefully consider the datasets for which you truly need column profile information. Refer to Compute consumption and cost considerations for more detail.
The example configuration below uses a wildcard character (%) to specify that, during a scan, Soda captures the column profile information for all the columns in the dataset named retail_orders. The . in the syntax separates the dataset name from the column name. Since _ is a wildcard character, the example escapes the character with a backslash \. Note that your data source may not support backslashes to escape a character, so you may need to use a different escape character.
profile columns:
columns:
- retail\_orders.%
You can also specify individual columns to profile, as in the following example.
profile columns:
columns:
- retail\_orders.billing\_address
- fulfillment.discount
Refer to the top of the page for more example configurations for column profiling.
Disable column profiling
If you wish to disable column profiling and any automated anomaly detection checks completely so that Soda Cloud profiles no columns at all, you can use the following configuration.
profile columns:
columns:
- exclude %.%
Access column profile information
After you have added the data source in Soda Cloud and the first scan to profile your data is complete, you can review the profiled columns in Soda Cloud.
Navigate to the Datasets dashboard, then click a dataset name to open the dataset’s info page.
Access the Columns tab to review the datasets that Soda Library discovered, including the column profile details you can expand to review as in the example below.
If you have requested access and activated an anomaly dashboard for a dataset, access the Anomalies tab to review the automated anomaly detection checks that Soda applied to your data based on the profiling information it collected.
Add quotes to all datasets
If your dataset names include white spaces or use special characters, you must wrap those dataset names in quotes whenever you identify them to Soda, such as in a checks YAML file.
To add those necessary quotes to dataset names that Soda acts upon automatically – discovering, profiling, or sampling datasets, or creating automated monitoring checks – you can add a quote_tables configuration to your data source, as in the following example.
data_source soda_demo:
type: sqlserver
host: localhost
username: ${SQL_USERNAME}
password: ${SQL_PASSWORD}
quote_tables: true
Compute consumption and cost considerations
Both column profiling and dataset discovery can lead to increased computation costs on your data sources. Consider adding these configurations to a select few datasets to keep costs low.
Discover Datasets
Dataset discovery gathers metadata to discover:
- the datasets in a data source
- the columns that datasets contain
- the data type of columns
Profile Columns
Column profiling aims to issue the most optimized queries for your data source, however, given the nature of the derived metrics, those queries can result in full dataset scans and can be slow and costly on large datasets. Column profiling derives the following metrics:
Numeric Columns
- minimum value
- maximum value
- five smallest values
- five largest values
- five most frequent values
- average
- sum
- standard deviation
- variance
- count of distinct values
- count of missing values
- histogram
Text Columns
- five most frequent values
- count of distinct values
- count of missing values
- average length
- minimum length
- maximum length
Inclusion and exclusion rules
- If you configure
discover datasetsorprofile columnsto include specific datasets or columns, Soda implicitly excludes all other datasets or columns from discovery or profiling. - If you combine an include config and an exclude config and a dataset or column fits both patterns, Soda excludes the dataset or column from discovery or profiling.
- Soda performs the Discover datasets and Profile datasets actions independently, relative to each other. If you configured
discover datasetsto exclude a dataset but do not explicitly also exclude its columns inprofile columns, Soda discovers the dataset and profiles its columns. For example, if, fordiscover datasets, you exclude all datasets that begin withstaging_, then configureprofile columnsto include all datasets, Soda discovers and profiles all datasets.
Limitations and known issues
- Known issue: Currently, SodaCL does not support column exclusion for the column profiling and dataset discovery configurations when connecting to a Spark DataFrame data source (
soda-library-spark-df). - Known issue: SodaCL does not support using variables in column profiling and dataset discovery configurations.
- Data type: Soda can only profile columns that contain NUMBERS or TEXT type data; it cannot profile columns that contain TIME or DATE data.
- Spark: Soda usually uses the profiling include/exclude pattern to build the query that retrieves a dataset’s metadata, but Spark does not support such profiling. Instead, Soda retrieves all the datasets in a schema, then filters the list based on the include/exclude pattern, changing all
%wildcard values with.*to translate a SQL pattern into a regular expression pattern. - Performance: Both column profiling and dataset discovery can lead to increased computation costs on your data sources. Consider adding these configurations to a selected few datasets to keep costs low. See Compute consumption and cost considerations for more detail.
- Workaround: If you wish, you can indicate to Soda to include all datasets in its dataset discovery or column profiling by using wildcard characters, as in
%.%. Because YAML, upon which SodaCL is based, does not naturally recognize%.%as a string, you must wrap the value in quotes, as in the following example.profile columns: columns: - "%.%"
Go further
- Need help? Join the Soda community on Slack.
- Learn more about the anomaly dashboard for datasets.
- Reference tips and best practices for SodaCL.
- Use a freshness check to gauge how recently your data was captured.
- Use reference checks to compare the values of one column to another.
Was this documentation helpful?
What could we do to improve this page?
- Suggest a docs change in GitHub.
- Share feedback in the Soda community on Slack.
Documentation always applies to the latest version of Soda products
Last modified on 17-Jul-24